A Virtual World for Engineering Design Teams
This chapter presents a model of a virtual world for small engineering design teams (one to five), centered on the product they are designing, including its subsystems and relevant ‘physics’, and also the way consumers interact with products during the course of consumption.
Product Architecture
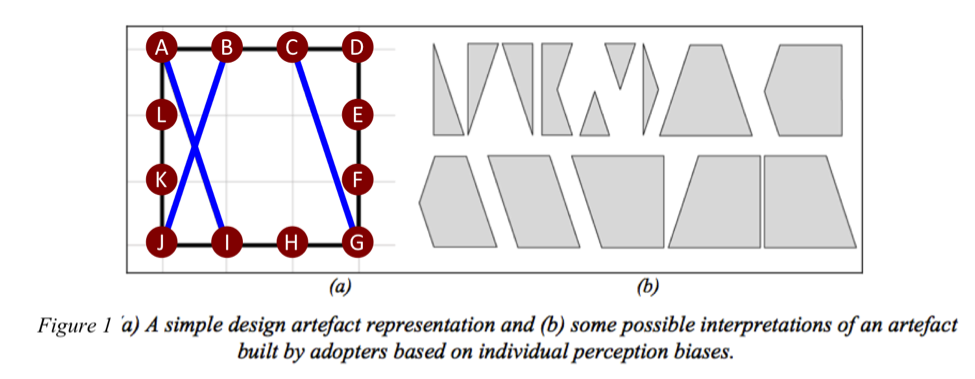
Figure 1 shows the architecture for the products being designed and consumed refp:sosa_computational_2005. There is a square perimeter with 12 fixed anchor points evenly spaced, and some number of lines between pairs of anchor points (that are not on the same side of the square). There are two distinct viewpoints on the product: 1) designers, and 2) consumers. The designer team’s view is this configuration of anchor points and lines (Figure 1a). Consumers “consume” a product by tracing convex polygons (Figure 1b), and there are many possible tracings for any given physical configuration.
Physical and Euclidean Manifestations
Products will be conceived as having a physical manifestation in addition to the Euclidean/Topological/Graph Theory manifestation. Broadly, we can conceive of the end Product as being analogous to a complex chemical molecule (e.g. a protein, an antibody, a catalyst, or similar). The Consumer’s perception/valuation/utility functions would be analogous to using the complex chemical molecules in a medical or manufacturing setting, where the “value” or “performance” of the molecule depends on protein folding or other molecular capabilities/processes of that sort.
We can define a physical manifestation of the Consumer’s usage of the Product. Let’s say that the act of tracing a Hamiltonian cycle exerts a physical force on the Product. Longer lines will be subject to more force than shorter lines. Lines that are traced multiple times will have to endure more force than those that are traced only once (or not at all). Lines that are bonded to each other in the middle of the square will have more strength to resist this force than those that do not. We can even define one or more “failure modes” relative to this force of usage. First, we could define “catastrophic failure” as a Product that simply breaks because it is too fragile relative to the normal usage forces. Second, we could also define “distortion failure” as a Product that flexes too much under usage force and therefore does not adequately maintain it’s Euclidean shape.
Subsystems
Seen this way, the tasks for designers can be associated with three interrelated “subsystems” plus System Design:
- Materials – the properties, capabilities, and costs of the raw materials that constitute main components of the Product (Lines and Joints/Bonds).
- Joints/Bonds – the properties, capabilities, and costs of the components that hold together the raw materials.
- Assembly Process – the properties, capabilities, and costs of processes that convert raw materials and joints/bonds into the final product.
- System Design – making choices among a range of compatible portfolios of Materials + Joints/Bonds + Assembly Processes.
Materials Subsystem
The raw materials would be for two purposes: 1) Lines, and 2) Bonds. We could define a space of possible raw materials according to a pre-defined set of characteristics – e.g. resistance to breaking, resistance to bending, workability, weight, cost, etc. Lines have physical characteristics of length, thickness, and weight, and (abstractly) are subject to associated forces in assembly and Consumer usage. Bonds have physical characteristics associated with the geometry of a specific arrangement of Lines and Vertexes. Lines could be bonded end-to-end to yield long lines.
As is typical in Nature, the most abundant and accessible raw materials would be the least desirable while those with conceptually ideal characteristics would be rare or even non-existent. Designers face an exploration-exploitation challenge. It takes trial-and-error learning to get good at using any raw material, which favors exploiting the raw materials they already use. But breakthrough designs might result if new raw materials are explored or discovered. The pressure on Designers of materials will depend on the complexity and demands of the target design and also on the capabilities of the other two sub-systems.
Joints/Bonds Subsystem
As a subsystem, the function of Joints/Bonds is to bring together Lines and Vertices in certain geometric configurations (“joint”) and to hold them together to endure the forces of manufacturing and usage (“bond”). In our Product architecture, every place a Line touches a Vertex or a Line crosses a Line is an opportunity for a Joint/Bond component. In Figure 1a, where Line A-I crosses Line B-J is an opportunity for a Joint/Bond. Only at the Vertexes (e.g. A, B, C…) are Joints/Bonds required.
Specific Joint/Bond designs might be specialized for a specific geometry (i.e. 90º angles and two lines at a time) or might be more general (flexible for any angle between 30º and 90º, and two or three lines at a single joint). Raw materials would have varying capability to support each of these Joint/Bond designs. The same raw material might be suitable for both Lines and Joints/Bonds of a certain type, while other designs might utilize very different raw materials for Lines as compared to Joints/Bonds. More complex Joint/Bond designs would be more difficult to manufacture and assemble and would be more prone to failures of both types listed above. Designers could overcome these difficulties through learning-by-doing and also possibly with design breakthroughs.
We can define a space of possible Joint/Bond designs based on a specified list of characteristics: joint angles, number of lines that can be joined, fixed or variable joint angles, and so on. It should be possible to give each possible design a “complexity” score and thus to create a partial order of design alternatives. This would support a cost function based on complexity, but also a gradient of design difficultly.
Assembly Process Subsystem
We can conceive of the assembly process as a set of instructions and recipes, where a “recipe” is looser and more flexible than instructions (which might be good or bad, depending on the context of manufacturing).
Like the other two subsystems, we can define a space of possible assembly processes relative to the cost and quality of output, relative to specific “baskets” of raw materials, Joint/Bond designs, and aggregate design configurations. For example, the simplest assembly process might only be able to reliably build the simplest product designs, constituted of simple/cheap/unsophisticated raw materials (implying short Lines) and the simplest Joints/Bonds. A somewhat more sophisticated process might do well with regular and repeating patterns of Lines and Joints (e.g. a lattice) but might be incapable of assembling irregular designs. The most sophisticated processes might be capable of assembling the most advanced raw materials using the most complicated Joints/Bonds, but might also be “overkill” for much simpler designs.
System Design
There is potential for system design work using this scheme, as distinct from subsystem design. I wouldn’t say that it’s required in a minimal Team, however. It’s possible to have a Team consisting of three sub-teams (one or more Designer for each sub-team) and, thus, the system design would emerge implicitly through their interactions and independent actions. System design could also be a topic of explicit reasoning, negotiation, and deliberation among subsystems and sub-teams.
In this proposed scheme, a System Designer would make choices among a range of compatible portfolios of Materials+Joints/Bonds+Assembly Processes. This would require that System Design agents have some model of what constituted compatibility between the subsystems and, conversely, how conflict between subsystems arise. This might entail building and testing mental models of the design process for each subsystem and also mental models of how they interact to yield the final Product. These mental models might be tacit or explicit, or both.
Modeling Material Process Design
The following is a very simple model for Material process design. There are two classes of materials: 1) Lines and 2) Bonds. The materials design process involves making decisions about A) inputs, and B) transformation/synthesis process, that together yield a batch of materials with the desired physical characteristics.
Material Characteristics
Lines have the following physical characteristics :
- Length
- Thickness
- Density
- Stiffness
- Brittleness
- Workability
- Bonding Compatibility (i.e. degree of compatibility to bond materials)
- Cost per unit weight
- Total cost )
Bond materials have the following physical characteristics :
- Bonding Compatibility (i.e. degree of compatibility with line materials)
- “Muscle” (Strength)
- Fatigue succeptability
- Cost per unit
Inputs
For inputs (a.k.a. raw material), we’ll define four somewhat-idealized classes:
- “Bio” – natural substances harvested from nature and produced by biological processes (e.g. wood, sap, etc.)
- “Metal” – refined metals that can be shaped and transformed
- “P-Synthetic” – plastic-like materials
- “G-Sythetic – crystaline materials (e.g. glass, graphite, etc)
- “Chemical” – reactive chemicals that modify, catalyize, or transform other materials through thermo-chemical reactions.
To simplify, we’ll assume that these inputs are binary – present or not present – and therefore there will be unique input combinations. (The “minus one” eliminates the empty input combination.) Example input sets :
- Bio only:
- Bio + Metal:
- P-Synthetic + Chemical:
Further constraining the design process, Nature requires that Bond materials always include the Chemical input. Either the Chemical alone is “sticky” enough to bond, or it transforms the other material into something “sticky” and bond-like. Therefore, the number of unique combinations for Bond inputs are , including Chemical alone.
We’ll define the states of Nature for these inputs in two ways. First, we define input-independent probability of acheivement (i.e. high probability = ‘easy’, low probability = ‘hard’).
Note: There is a little shorthand in notation in the following rules. is short for , which reads:
“The probability of acheiving length greater than the target , given that the target length is small (i.e. approaches the minimum length).”
- Length:
- Thickness:
- Density
- Stiffness
- Brittleness
- Workability
- Cost per unit weight
Translating: it’s harder to make long lines than short lines; harder to make thick lines than normal, and much harder than very thin lines; and similar for density and stiffness. It’s harder to make a line that less brittle than one that is more brittle. It is harder to make a line that is more workable than one that is less workable. Finally, it is easier to make lines with high unit cost than lines will very low costs.
Second, taking each material as a solo input, we will define the probability of being transformed into each of the (desired) physical characteristics (e.g. is the desired length, which is bounded by and ). We’ll define the ordinal ranking of these probabilities:
- Length : , as
- Thickness :
- as
- as
- Density : , as
- Stiffness : , as
- Brittleness : , as
- Workability , as
- Cost per unit weight : , as
Let me translate the first line: If you are trying to produce a long line, it is much easier (higher probability) to do this using Bio (e.g. wood) than Metal, and Metal is easier than P-Synthetic (e.g. plastic), and easier than G-Synthetic (e.g. glass). All these are much easier than trying to produce a long line using Chemical alone, will probability almost equal to zero.
If all this sounds complicated (like: “how are we ever going to model agent reasoning and learning?”) – don’t worry. Abstraction is our friend! Behold
Transformation Process
We will model the Transformation process as a function mapping from the vector of inputs to a Material characteristics vector, given a vector of process characteristics \Theta.
Since any function can be defined and implemented as a lookup table (given enough memory!), we will synthesize* the function as a lookup table (of sorts) using random variables and conditioning that impose contraints consisetent with the probability structures listed above.
*Why this approach and not some other? For example, many papers that look at search or optimization on rugged landscapes simply draw from probability distributions for each performance/outcome variable. The problem with this approach is that (generally) all points in the landscape are independent of all the others, including neighbors. So if A and B are similar input and process characteristic vectors, there is nothing to be gained by "learning" about A in order to improve your estimate of B. In contrast, we need to have meaningful similarity in outcomes given similar inputs.
Another approach you might imagine would be to define T(I,\Theta) as high degree polynomials with some noise terms. While that might work, it imposes more experimentor bias/preference than I think is necessary. We really want to be ignorant of the details of this (and other) performance landscapes, as long as those landscapes have the right general characteristics
I don’t want to be specific about the nature of these Transformation processes, and therefore I’d like to treat the vector of process characteristics \Theta as abstractly as possible, while still preserving the notion that each characteristic has some semantic value to designers (Actors), and also enabling a mechanism for detecting degree of similarity between any two characteristic vectors: ; .
I am not so sure that SDR is the right way to go
I going to try using Sparse Distributed Representations** (SDR) for product characteristic vectors.
**Since 1988 [add reference], SDRs have been used in human-centered AI to model how the human neocortex represent complex streams of “inputs”, either sensory inputs or signals from other neural systems or biochemical systems. Numenta, a privately held product and research company in Redwood City, CA, has been the most steadfast advocate, champion, and center of research on SDRs and cognitive systems built on top of them. See the book On Intelligence for an accessable description and motivation for SDRs
SDRs are very large binary vectors (from a few hundred to thousands of bits), where there are a fixed proportion of bits that are “on” for all valid encodings. (The formal term is “Norm” “The norm of point x is the number of ones in its binary representation.” Some implementations might have a soft max norm instead of fixed, but we will go with a fixed norm that we set to meet our needs).
Each bit in an SDR is, presumptively, semantically meaningful. The length of the SDR vector is chosen to be much larger than the most condensed (i.e. cannonical) vector of characteristics and values for each characteristic.
The key feature of SDRs, for our purposes, is that it is very easy to calculate similarity between two SDR encodings. The operation is simply counting the number of matching ones, divided by the norm. If they perfectly match, then . If no match, then . We just need to pick a SDR length and to give us the right discriminant capabilities.
There are many ways to encode semantic data into an SDR of a given length. Since we won’t assume anything about the length and encoding of the elements in , we’ll go with a random encoding.
We have to be thoughtful about implementation, because we don’t want to blindly implement a loop through possible encodings during initialization. (Fun fact: , and it is 284 orders of magnitude greater than the number of seconds since the Big Bang ( seconds).)
From Wikipedia: “It is impossible to reserve a separate physical location corresponding to each possible input; SDM implements only a limited number of physical or hard locations. The physical location is called a memory (or hard) location.”
We will start with an SDR length of 200 and = 0.2 (i.e. 40 one’s out of 200).
What we will do is to generate a modestly-sized set of initialization points, where each initialization point is minimally matched to only one, two, or three other points in the initialization set. I say “modestly-sized” only in relation to the astronomical size of the SDR code space. As a start, I will try at 5 times the length of the SDR vector: e.g. 1,000 initialization points for an SDR of length 200 and = 0.2.
We will store each SDR as an address concatentated with the output vector, where “address” is an integer list of vector indexes that are set to 1. The address will always be a vector of 40 integers ().
Instead of this implementation, should probably use the Javascript library for SDR:
var N = 200;
var norm = 0.2;
var num_ones = Math.round(N * norm);
var num_init = 5 ; //N * 5;
var removeIndexed = function(i, arr){
// remove the ith element in arr
var first = arr.slice(0,i );
var second = arr.slice(i + 1, arr.length );
return Array.prototype.concat(first, second);
}
var isIn = function(y,arr){
if (arr.length > 0){
return any(function(x) { return x === y; }, arr);
} else {
return false;
}
}
// Remove duplicates from a sorted array
var dedup = function(arr){
var nodup = reduce(function(z,acc){return isIn(z,acc) ? acc : [z].concat(acc); },[],arr);
return nodup;
}
var minArray = function(arr){
return reduce(function(x,acc){return x < acc ? x : acc},arr[0],arr);
}
var maxArray = function(arr){
return reduce(function(x,acc){return x > acc ? x : acc},arr[0],arr);
}
// recursive function
var addIfNotIn = function(arr, mask, result){
// return all elements of arr that are NOT in mask
if (arr.length == 0){
return result;
} else {
var x = first(arr);
if (any(function(y){return y ==x;}, mask) ){
var newResult = result;
var newArr = removeIndexed(0,arr);
return addIfNotIn(newArr,mask, newResult);
} else {
var newResult = Array.prototype.concat(result,x);
var newArr = removeIndexed(0,arr);
return addIfNotIn(newArr,mask, newResult);
}
}
}
var drawAgain = function(n, results, count){
if (count <= 0){
return results;
} else {
var draw = sample(RandomInteger({n:n}));
var isNotNew = any(function(x){return draw==x;}, results);
var newResults = isNotNew
? results
: Array.prototype.concat(results, draw);
var newCount = isNotNew
? count
: count - 1;
return drawAgain(n,newResults, newCount);
}
}
var drawN = function(n, arr){
// return n randomly selected elements from arr
var drawIndexes = drawAgain(arr.length, [ ],n);
return map(function(x){return arr[x];},drawIndexes);
}
/*
var drawN = function(n, arr){
// return n randomly selected elements from arr
var allElements = mapN(function(x){return x;}, arr.length);
var drawCount = mapN(function(x){return x;}, n);
var result = reduce(
function(x, acc){
var drawIndex = sample(RandomInteger({n:arr.length}));
var element = arr[drawIndex];
var newElements = removeIndexed(drawIndex, acc.elements);
var newData = Array.prototype.concat(acc.data, element);
return {
elements: newElements,
data: newData
}
}, { elements: allElements, data :[ ] }, drawCount);
return result.data;
}
*/
var drawRandom = function(arr, counter, result){
if (counter <= 0){
return result;
} else {
var drawIndex = sample(RandomInteger({n:arr.length}));
var element = arr[drawIndex];
var nextResult = Array.prototype.concat(result, element );
var nextCounter = counter - 1;
var nextArr = removeIndexed(drawIndex, arr);
return sort(drawRandom(nextArr, nextCounter, nextResult));
}
}
var genRandomSDRaddress = function(n,o){
// generate a vector (length o) of random integers between 0 and n - 1
// first, create an array of all possible indexes in the SDR
var allIndexes = mapN(function(x){return x;},n - 1);
// draw o indexes randomly, without replacement
return drawRandom(allIndexes, o, [ ]);
}
/*
// recursive function OLD
var genSDR = function(n,o,c,
unallocatedIndexes,
allocatedIndexes,
result,
count){
if (count <= 0){
return result;
} else {
// first time through, only draw from unallocatedIndexes
var sdr1 = allocatedIndexes.length != 0
? drawRandom(unallocatedIndexes, o - c, [ ])
: drawRandom(unallocatedIndexes, o, [ ]);
var sdr2 = (allocatedIndexes.length != 0)
? drawRandom(allocatedIndexes, c, [ ])
: [] ;
var sdr = sort(Array.prototype.concat(sdr1, sdr2));
var newUnallocatedIndexes = reduce(function(x,acc){
return remove(x,acc);}, unallocatedIndexes, sdr);
var newAllocatedIndexes = sort(
Array.prototype.concat(allocatedIndexes,sdr ));
var newResult = Array.prototype.concat(result, [sdr]);
var newCount = count - 1;
return genSDR(n,o,c,
newUnallocatedIndexes,
newAllocatedIndexes,
newResult,
newCount)
}
}
var genCoupledSDRsOLD = function(k,n,o,c){
// generate k vectors of length o, each
// consisting of random integers between 0 and n - 1
// BUT with at least c common indexes between
// first, create an array of all possible indexes in the SDR
var unallocatedIndexes = mapN(function(x){return x;},n - 1);
return genSDR(n,o,c, unallocatedIndexes, [ ], [ ], k);
}
*/
// recursive function
var genUncoupledSDR = function(n,o,c,
unallocatedIndexes,
allocatedIndexes,
result,
count){
if (count <= 0){
return result;
} else {
var sdr = drawRandom(unallocatedIndexes, o - c, [ ]);
var newUnallocatedIndexes = reduce(function(x,acc){
return remove(x,acc);}, unallocatedIndexes, sdr);
var newAllocatedIndexes = sort(
Array.prototype.concat(allocatedIndexes,sdr ));
var newResult = Array.prototype.concat(result, [sdr]);
var newCount = count - 1;
return genUncoupledSDR(n,o,c,
newUnallocatedIndexes,
newAllocatedIndexes,
newResult,
newCount);
}
}
var genCoupledSDRs = function(k,n,o,c){
// generate k vectors of length o, each
// consisting of random integers between 0 and n - 1
// BUT with at least c common indexes between
// first, create an array of all possible indexes in the SDR
var unallocatedIndexes = mapN(function(x){return x;},n - 1);
// generate k vector of length o - c with no overlap
var uSDRs = genUncoupledSDR(n,o,c, unallocatedIndexes, [ ], [ ], k);
var allocated = dedup(sort(reduce(
function(x,acc){
return Array.prototype.concat(x,acc);},[ ], uSDRs)));
// now create an array, one for each SDR, removing it's own allocated
// indexes. (Selecting from self does not create coupling!)
var allocatedK = mapN(
function(x){
return map(function(y){
return remove(
function(z){return z==y;},allocated)},uSDRs[x]);
},k);
var cSDRs = mapN(
function(x){
return drawN(c,allocatedK[x])
;},k);
var sdrs = map2(
function(x,y){
return Array.prototype.concat(x,y);},uSDRs,cSDRs);
return sdrs;
}
var modSDRaddress = function(sdr){
// randomly pick one SDR index to swap with another not currently set = 1
var allIndexes = mapN(function(x){return x;},N - 1);
var availableIndexes = addIfNotIn(allIndexes,sdr,[]);
// pick one to drop
var dropIndex = sample(RandomInteger({n: sdr.length}));
var newSDR = removeIndexed(dropIndex, sdr);
// pick one to add
var addIndex = sample(RandomInteger({n: availableIndexes.length}));
return sort(Array.prototype.concat(newSDR, availableIndexes[addIndex]) );
}
// return similarity between two SDRs
var similarityP = function(sdr1, sdr2){
return reduce(function(x,acc){
return any(function(y){return x==y;},sdr2) ? acc + 1 : acc;
},0,sdr1);
}
// test for min and max similarity in an array of SDRs
var similarityPairwise = function(arr){
var allIndexes = mapN(function(x){return x;},arr.length - 1);
var results = reduce(function(x,acc){
var alterIndexes = mapN(function(y){return y + x + 1;},arr.length - x - 1);
return Array.prototype.concat(acc,
map(function(z){return similarityP(arr[x],arr[z]);},alterIndexes)
);
}, [], allIndexes);
return results;
}
// test for overall similarity in an array of SDRs,
// Where similarity for any SDR is the *max* overlap with *any* other SDR
var similarity = function(arr){
var allElements = mapN(function(x){return x;},arr.length);
var results = reduce(function(x,acc){
var alterIndexes = remove(x,allElements);
//mapN(function(y){return y + x + 1;},arr.length - x - 1);
return
Array.prototype.concat(acc,
maxArray(
map(function(z){
return similarityP(arr[x],arr[z]);},alterIndexes)
)
);
}, [], allElements);
return results;
}
var test = genCoupledSDRs(50,20000,20,3);
Simple Process Elements: Line Production, Joint Production, and and Mixer
As an alternative to the process in the previous section, here is a set of simple process elements that does not use full characteristics of Lines and Joints. Lines only have length and Joints only have minAngle and maxAngle (between 0° and 90°).
// batch sizes
var numLines = 2000;
var numJoints = 10000;
var numFrames = 500;
var marginOfError = 0.03;
var maxLineLength = 1.41421356237 * (1 + marginOfError); // sqrt(2)
// "Physics" of Lines, Joints, and Assembled Products
///fold:
// Feasable line lengths
var a = 1.41421356237 // sqrt(2)
var b = 1.20185042515 // sqrt(1 + (2/3)2)
var c = 1.05409255339 // sqrt(1 + (1/3)2)
var d = 1.0
var e = 0.94280904158 // sqrt((2/3)2 + (2/3)2)
var f = 0.7453559925 // sqrt((1/3)2 + (2/3)2)
var g = 0.47140452079 // sqrt((1/3)2 + (1/3)2)
var feasableLines = [a,b,c,d,e,f,g];
var feasableLabels = ["a","b","c","d","e","f","g"];
// Line configurations
var aLines = ["AG", "DJ"];
var bLines = ["AF","AH","BG","CJ","DI","DK","EJ","GL"];
var cLines = ["AE","AI","BH","BJ","CG","CI","DH","DL","EK","FJ","FL","GK"];
var dLines = ["BI","CH","EL","FK"];
var eLines = ["BF","CK","EI","HL"];
var fLines = ["BE","BK","CF","CL","EH","FI","HK","IL"];
var gLines = ["BL","CE","FH","IK"];
var configurations = [aLines,bLines,cLines,dLines,eLines,fLines,gLines];
// joint angle requirements
var aAngles = [45,45];
var bAngles = [33.69, 56.31];
var cAngles = [18.43, 71.57];
var dAngles = [90,90];
var eAngles = [45,45];
var fAngles = [26.57, 63.43];
var gAngles = [45,45];
var angles = [aAngles,bAngles,cAngles,dAngles,eAngles,fAngles,gAngles];
// Number of configurations for each feasable length
var maxA = 2;
var maxB = 8;
var maxC = 12;
var maxD = 4;
var maxE = 4;
var maxF = 8;
var maxG = 4;
var convertToCannonical = function(arr){
var mapR1 = {
"A":"D",
"B":"E",
"C":"F",
"D":"G",
"E":"H",
"F":"I",
"G":"J",
"H":"K",
"I":"L",
"J":"A",
"K":"B",
"L":"C"
};
var mapR2 = {
"A":"G",
"B":"H",
"C":"I",
"D":"J",
"E":"K",
"F":"L",
"G":"A",
"H":"B",
"I":"C",
"J":"D",
"K":"E",
"L":"F"
}
var mapR3 = {
"A":"J",
"B":"K",
"C":"L",
"D":"A",
"E":"B",
"F":"C",
"G":"D",
"H":"E",
"I":"F",
"J":"G",
"K":"H",
"L":"I"
}
var result1 = sort(map(function(str){
return sort(map(function(x){return mapR1[x];},str.split(''))).join('');},
arr));
var result2 = sort(map(function(str){
return sort(map(function(x){return mapR2[x];},str.split(''))).join('');},
arr));
var result3 = sort(map(function(str){
return sort(map(function(x){return mapR3[x];},str.split(''))).join('');},
arr));
var cannonical = sort([arr,result1,result2,result3]);
return cannonical[0];
}
///
// Helper functions
///fold:
// replace the ith element in arr with val, returning new array
var replaceIndexed = function(i,val, arr){
return i < 0 || i >= arr.length || val == null
? arr
: mapIndexed(function(j,x){return j==i? val : x}, arr);
}
var flatten = function(arr){
return [].concat.apply([], arr);
}
var head = function(arr){
var limit = 10;
return remove(null,mapN(function(i){
return i < arr.length
? arr[i]
: null},
limit));
}
var drawAgain = function(arrLen, results, count){
if (count <= 0){
return results;
} else {
var draw = sample(RandomInteger({n:arrLen}));
var isNotNew = any(function(x){return draw==x;}, results);
var newResults = isNotNew
? results
: Array.prototype.concat(results, draw);
var newCount = isNotNew
? count
: count - 1;
return drawAgain(arrLen,newResults, newCount);
}
}
var drawNindexed = function(n, arr){
// return n randomly selected elements and their indexes from arr
var drawIndexes = drawAgain(arr.length, [ ],n);
return {value: map(function(x){return arr[x];},drawIndexes),
indexes: drawIndexes};
}
var drawN = function(n, arr){
// return n randomly selected elements and their indexes from arr
var drawIndexes = drawAgain(arr.length, [ ],n);
return map(function(x){return arr[x];},drawIndexes);
}
var removeIndexed = function(i, arr){
return remove(null,mapIndexed(function(j,x){
return j === i ? null : x;}, arr));
}
var removeIndexedArray = function(indArr, arr){
var indexes = indArr instanceof Array ? indArr : [indArr];
return remove(null,mapIndexed(function(j,x){
return indexes.includes(j) ? null : x;}, arr));
}
var ChiSquare = function(n){
// "ChiSquare is a special case of the gamma distribution"
// http://www.math.uah.edu/stat/special/ChiSquare.html
//"For n > 0, the gamma distribution with shape parameter n/2
// and scale parameter 2 is called the chi-square distribution
// with n degrees of freedom."
return Gamma({scale: n/2, shape: 2})
}
///
//-------------------------------------
// line production
// create an array of lines of various lengths
var lines = repeat(numLines, function(){return maxLineLength * beta(1,1);});
//-------------------------------------
// joint production process
var makeJoint = function(){
var nominalAngle = sample(RandomInteger({n:91}));
// uniform on 0 to 90 degrees;
var sigma = sample(ChiSquare(5));
var minAngle = Math.max(0,nominalAngle - 2*sigma);
var maxAngle = Math.min(90,nominalAngle + 2*sigma);
var minAngleNorm = (minAngle > maxAngle) // make sure min < max
? maxAngle
: minAngle;
var maxAngleNorm = (minAngle > maxAngle)
? minAngle
: maxAngle;
return {min: minAngle,
max: maxAngle}
}
// joint production
var joints = repeat(numJoints,makeJoint);
//-------------------------------------
// return line labels corresponding to elements in arrRef == arrTest +/- MOE
// (Margin of Error)
var findLineMatches = function(arrRef, arrTest, MOE, labels){
var matchingIndexes = sort(remove(null,
map(function(x){
return remove(null,mapIndexed(function(i,y){
return x < y * (1 + MOE) && x > y * (1 - MOE)
? i : null; },arrRef))[0];}, arrTest))
);
return matchingIndexes.length > 0
? {labels : map(function(i){return labels[i];},matchingIndexes),
indexes: matchingIndexes}
: {labels : null,
indexes: null};
}
var findJointMatches = function(anglePair, acc){
if (!acc.successful){ // if it failed once, then don't process more matches
return {joints: acc.joints,
indexes: acc.indexes,
available: acc.available,
successful: false
}
} else {
// find matching joints for *both* angles, otherwise return null
var matchA = remove(null,mapIndexed(function(i,x){
return anglePair[0] >= x.min && anglePair[0] <= x.max
? i
: null
},acc.available)) ;
// nullify this match to avoid duplicates
var matchAindex = matchA.length > 0 ? matchA[0] : null;
var newJointsArr = matchAindex != null
? replaceIndexed(matchAindex,{min:-1,max:-1},acc.available)
: acc.available;
var matchB = remove(null,mapIndexed(function(i,x){
return anglePair[1] >= x.min && anglePair[1] <= x.max
? i
: null
},newJointsArr));
var matchBindex = matchB.length > 0 ? matchB[0] : null;
var newJointsArr = matchBindex != null
? replaceIndexed(matchBindex,{min:-1,max:-1},newJointsArr)
: newJointsArr;
return matchA.length > 0 && matchB.length > 0
? {joints: acc.joints.concat([acc.available[matchAindex],acc.available[matchBindex]]),
indexes: acc.indexes.concat([matchAindex,matchBindex]),
available: newJointsArr,
successful: acc.successful
}
: {joints: acc.joints,
indexes: acc.indexes,
available: acc.available,
successful: false
};
}
}
// NEW FUNCTION -- COMPOUND LINES
// if there are any joints allowing 0° joint,
// check if one or more lines can be combined
// to build a feasable line
// special purpose function
// "record" is an accumulator, with
// properties: "result", "config", "droppedIndexes" and "counter"
var drawOneAccumulate = function(i, record){
// if no config options to draw, then add to droppedIndexes
if (record.config[i].length == 0){
return {results: record.results,
droppedIndexes: record.droppedIndexes.concat(record.counter),
counter: record.counter + 1,
config: record.config};
} else {}
var draw = sample(RandomInteger({n:record.config[i].length}));
var newResult = record.config[i][draw];
var newConfig = mapIndexed(function(j,x){
i == j
? removeIndexed(draw,x)
: x
},record.config);
return {results: record.results.concat(newResult),
droppedIndexes:record.droppedIndexes,
counter: record.counter + 1,
config: newConfig};
}
// Assembly process
var assemble = function(aLines, aJoints){
// match as many lines as possible to feasable lengths
var matchedLines = findLineMatches(feasableLines,
aLines.value,
marginOfError,
feasableLabels);
var isViable = matchedLines != null
&& matchedLines.labels != null
&& matchedLines.indexes != null
&& matchedLines.labels.length > 0
&& matchedLines.indexes.length > 0
var assembly = isViable
? reduce(function(i,acc){
return drawOneAccumulate(i,acc);}
, {results: [],
droppedIndexes: [], // index # of any lines dropped
// b/c no available slots
counter: 0,
config:configurations}
,matchedLines.indexes)
: null;
var isViable = isViable && assembly.results.length > 0
&& assembly.droppedIndexes.length < matchedLines.indexes.length;
// remove any lines that couldn't be positioned (no available slots)
var postionedLinesIndexes = isViable
? removeIndexedArray(assembly.droppedIndexes,matchedLines.indexes)
: null;
var anglePairs = isViable
? map(function(i){return angles[i];},postionedLinesIndexes)
: null;
var matchedJoints = isViable
? reduce(function(x,acc){
return findJointMatches(x,acc);},
{joints:[],
indexes:[],
available:aJoints.value,
successful: true},
anglePairs)
: {joints:[],
indexes:[],
available: aJoints.value,
successful: false} ;
var hasViableJoints = matchedJoints.successful;
// if there are viable joints and total number of matched lines > 0
// then isViable = true
var isViable = isViable && hasViableJoints;
var usedLinesIndexes = isViable
? map(function(i){
return aLines.indexes[i];},matchedLines.indexes)
: null;
// "internalIndexes" map to the aJoints index array
// thus, needs to be dereferenced before returning result
// (used to remove these indexes from the available joints)
var internalIndexes = isViable
? matchedJoints.indexes
: null;
var usedJointsIndexes = isViable
? map(function(i){return aJoints.indexes[i];},internalIndexes)
: null;
return isViable
? {product: convertToCannonical(assembly.results),
usedLineIndexes: usedLinesIndexes,
usedJointIndexes:usedJointsIndexes}
: null;
}
// prodution process
var mixingVat = function(availLines,
availJoints,
numAvailFrames,
finishedProducts,
count){
var K = 10;
if (count <= 0 || numAvailFrames == 0
|| availLines.length < K
|| availJoints.length < K * 5){
return {
unusedLines: availLines,
unusedJoints: availJoints,
numUnusedframes: numAvailFrames,
products: finishedProducts
};
} else {
// randomly draw K lines
var tLines = drawNindexed(K, availLines);
// randomly draw K * 5 joints
var tJoints = drawNindexed((K*5), availJoints);
// test to see if they can be assembled into a viable products
var assembledProduct = assemble(tLines, tJoints);
var isViable = assembledProduct != null ;
// if yes, then add the product to finishedProduct
var newFinishedProducts = isViable
? Array.prototype.concat(
finishedProducts, [assembledProduct.product])
: finishedProducts;
// and remove the drawn lines, joints, and frames from avail lists
// if not then make no changes
var newAvailLines = isViable
? removeIndexedArray(assembledProduct.usedLineIndexes,availLines)
: availLines;
var newAvailJoints = isViable
? removeIndexedArray(assembledProduct.usedJointIndexes,availJoints)
: availJoints;
var newNumAvailFrames = isViable
? numAvailFrames - 1
: numAvailFrames;
// call mixingVat() recursively
return mixingVat(newAvailLines,
newAvailJoints,
newNumAvailFrames,
newFinishedProducts,
count - 1
);
}
}
var result = mixingVat(lines, joints,numFrames,[],500 );
print("# products produced = " + result.products.length);
var prodLen = map(function(x){return x.length;},result.products);
var maxLen = Math.max.apply(null,prodLen);
viz.hist(prodLen,{numBins:maxLen});
var prodStrings =map(function(x){return x.join("-");},sort(result.products));
viz.hist(prodStrings);
To Do
- Finish Materials Design
- Add Joints Design
- Add Assembly Design
- Add System Design
Endnotes
1.↩ End note 1
References
cite:sosa_computational_2005